发布时间:2026-01-16 作者:admin
谷歌为LiteRT推出了一款名为高通AI引擎直通(QNN)的全新加速器,其目的是增强搭载骁龙8 SoC的高通安卓设备的AI性能。这款加速器能显著提升性能,和CPU执行速度相比,最多可快100倍;与GPU相比,则能快10倍。
尽管现代安卓设备大多都配备了GPU硬件,但谷歌的软件工程师卢王、Wiyi Wanf与安德鲁·王表示,仅仅依靠GPU来处理AI任务,或许会造成性能上的瓶颈。比如他们举例说,“在设备端运行一个计算量很大的文本转图像生成模型,同时还要用基于机器学习的分割技术处理实时相机画面”,这种情况就算是高端的移动GPU也可能难以应对。而这样一来,就有可能导致用户在使用时遇到画面卡顿、掉帧的问题。
然而,如今不少移动设备都搭载了神经处理单元(NPUs),作为专门的AI加速硬件,和GPU相比,它在处理AI工作任务时速度能有明显提升,而且耗电量也更低。
QNN由谷歌与高通深度协作研发而成,旨在取代此前的TFLite QNN代理方案。该框架整合了丰富的SoC编译器与运行时系统,并借助简洁的API向开发者开放,从而构建起统一且简化的开发流程。目前它已支持90项LiteRT操作,核心目标是达成完整模型委托——这正是实现最优性能的关键所在。此外,QNN还内置了专用内核与针对性优化,能进一步提升Gemma、FastLVM等大语言模型(LLM)的运行表现。
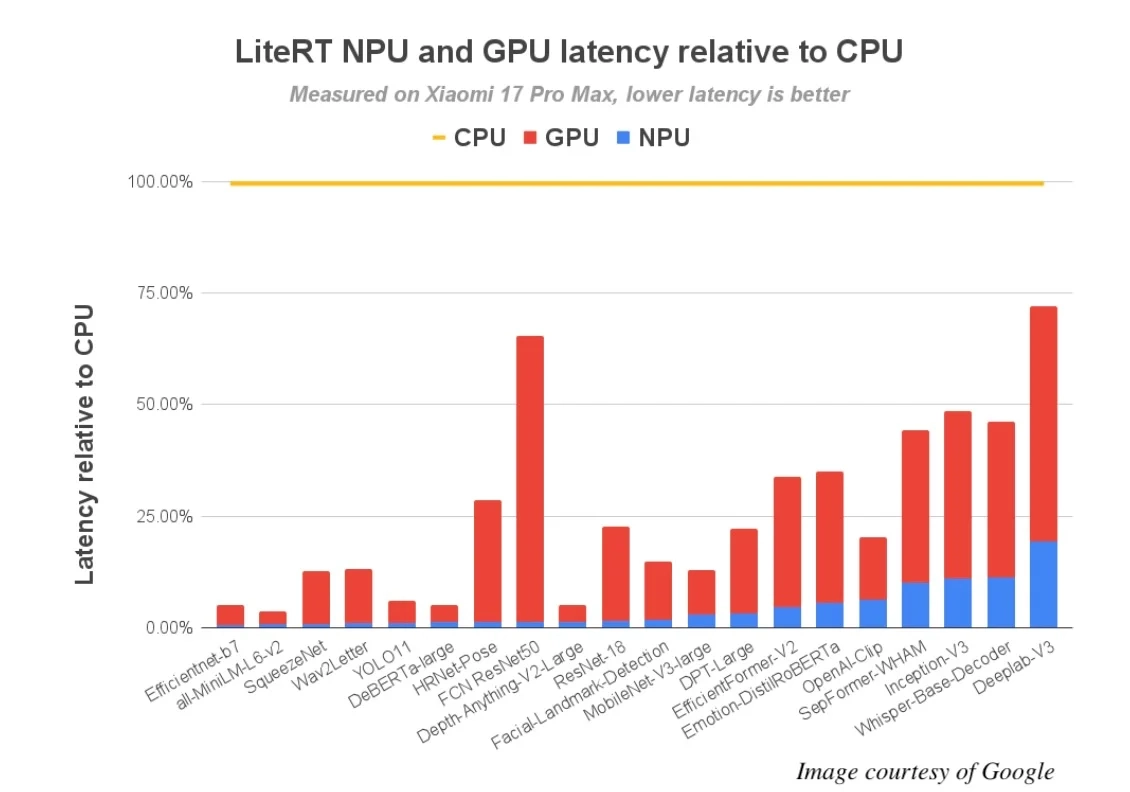
谷歌针对72个机器学习模型开展了QNN基准测试,在这些模型里,有64个顺利完成了完整的NPU委托。测试结果表明,和CPU执行的情况相比,性能提升最多可达100倍;与GPU相比,性能提升则为10倍。
在高通最新推出的旗舰级SoC——骁龙8 Elite Gen 5上,性能方面的提升十分突出:有超过56个模型在其NPU上的运行时间能控制在5毫秒以内,相比之下,在CPU上仅13个模型可以达到这样的速度。这一突破为众多此前难以实现的实时AI体验打开了大门。
谷歌工程师还打造了一款概念性应用,其采用了苹果FastVLM-0.5B视觉编码模型的优化版本。这款应用能够近乎实时地解读相机捕捉的现场画面。在骁龙8 Elite Gen 5 NPU平台上,针对1024×1024分辨率的图像,它的首次令牌生成时间(TTFT)仅需0.12秒,预填充速率突破11000令牌/秒,解码速度也超过100令牌/秒。苹果的该模型是通过int8权重量化与int16激活量化技术完成优化的。按照谷歌工程师的观点,这正是解锁NPU中性能强劲、运行高速的int16内核的核心所在。
QNN仅能在安卓系统的部分硬件上运行,这些硬件主要是搭载骁龙8和骁龙8+芯片的设备。若要开启使用,可前往NPU加速指南页面,并从GitHub下载LiteRT工具。

OpenAI借助谷歌TPU,在Nvidia芯片成本上节省了30%
攻略 · 2026-01-16 06:58:34

索尼被指“区别对待”?疑似测试动态游戏定价机制,不同玩家或面临不同价格
攻略 · 2026-01-16 06:43:21
影视飓风冲锋衣陷致癌与防水性争议风波小韩哥持续追问
攻略 · 2026-01-16 06:29:21

突发消息!西山居CEO郭炜炜宣布辞职,不过他将继续担任首席制作人一职
攻略 · 2026-01-16 06:14:25

uzi复出消息登上微博热搜!网友:能不能给个确切说法
攻略 · 2026-01-16 06:00:23
《怪奇物语》最终季新海报释出,主角为疯狂麦克斯,该剧豆瓣评分高达9.7分!
攻略 · 2026-01-16 05:46:18
发布于 2026-01-16 08:55:08

发布于 2026-01-16 08:38:25

发布于 2026-01-16 08:09:30

发布于 2026-01-16 07:55:26
发布于 2026-01-16 07:26:23

发布于 2026-01-16 07:12:22